
本文仅用于学习研究与技术交流,不构成任何投资建议。
之前在聚宽上看到不少大佬分享的 行业宽度展示 脚本,觉得特别酷。每天跑一下脚本,就能立刻知道最近资金在往哪些行业集中,哪些行业正在悄悄升温。
聚宽链接:https://www.joinquant.com/view/community/detail/55fabfea977bddeaf91f3e728c3e68a1
这种从“全市场视角”快速把握热点的感觉,就特别爽、特别酷炫。
不过,作为一名 本地 Python 量化 的强迫症患者,对于不能在本地 Python 环境运行的功能总觉得缺少点什么,总觉得不够带劲。
于是,我开始琢磨:如何将该功能在本地 Python 环境中实现。
数据
行业宽度的计算主要需要两方面的数据:
- 全市场的历史行情数据
- 股票所属的行业分类数据
幸运的是,这两样数据都可以从 Tushare 中取到。而 Tushare 数据的获取,对个人用户而言门槛也不高。
全市场行情
其中一个方法就是用 Tushare 的 pro.daily() 接口。该接口可以获取多只股票在某一段时间的行情,包括收盘价 close 等。
然而,这里有几个问题:
pro.daily()单次最多只能提取 6000 条数据;- 全市场股票有 5000 多只,如果一次性取长区间,很容易超过限制;
- 原始行情没有复权,直接用未复权价格做计算并不科学。
全市场股票数量很多,所以可以选择 分批获取,然后将获取的数据拼接起来。
# pro.daily 单次只能提取 6000 条数据,因此需要控制好每次提取数据的股票数
# https://tushare.pro/document/2?doc_id=27
price_all = []
stk_num = int(6000 / (count_ + 20) * 0.99)
# 每次提取一批股票的历史行情
for i in range(0, len(stock_list), stk_num):
idx_end = np.min([len(stock_list), i + stk_num])
joined_str = ",".join(stock_list[i:idx_end])
df = pro.daily(ts_code=joined_str, start_date=since, end_date=until)
price_all.append(df)
price_all = pd.concat(price_all)
price_all = price_all.set_index(["ts_code", "trade_date"])直接用未复权的数据搞计算肯定是不科学的。好在 pro.daily() 也可以返回昨收价(除权价)pre_close。有了 close、pre_close,我们就可以自己对数据进行复权,前复权、后复权都可以。
这就是自己在本地处理数据的好处:自由度大,想要什么样的处理方式就用什么样的处理方式。
def adjust_price(df: pd.DataFrame, label: str = "front") -> pd.DataFrame:
df_adj = df.copy()
adj_factor = df["close"] / df["pre_close"]
adj_factor = adj_factor.cumprod()
if label == "front":
df_adj["close"] = adj_factor / adj_factor.iloc[-1] * df["close"].iloc[-1]
elif label == "back":
df_adj["close"] = adj_factor / adj_factor.iloc[0] * df["close"].iloc[0]
df_adj["open"] = df["open"] / df["close"] * df_adj["close"]
df_adj["high"] = df["high"] / df["close"] * df_adj["close"]
df_adj["low"] = df["low"] / df["close"] * df_adj["close"]
return df_adj
# pro.daily 获取的行情是没有复权的,需要对数据进行复权
adjusted_list = []
for i, stk in enumerate(stock_list):
df = price_all.loc[stk]
df = df.sort_index()
df = adjust_price(df, "front")
df["ts_code"] = stk
df["date"] = df.index
df = df[["ts_code", "close", "date"]]
adjusted_list.append(df)
adjusted_list_all = pd.concat(adjusted_list)行业分类
我们首先可以用 Tushare 的 pro.index_classify() 接口获取申万一级行业分类列表,总共有 31 个分类。
# 获取申万一级行业列表
# https://tushare.pro/document/2?doc_id=181
df = pro.index_classify(level="L1", src="SW2021")
s_industry = df[["index_code", "industry_name"]]
s_industry.index = s_industry["index_code"]
s_industry = s_industry.drop(columns="index_code")
s_industry = s_industry.squeeze()
listcode_industry_all = s_industry.index.tolist()然后,可以用 pro.index_member_all() 接口获取每个行业所包含的票。有了这些信息,我们就可以映射每只票所属的行业。
# 获取所有一级分类信息及其所含股票
# https://tushare.pro/document/2?doc_id=335
df_all = []
for code in code_industry_all:
df = pro.index_member_all(l1_code=code)
df_all.append(df)
df_all = pd.concat(df_all)
# 获取股票所在的行业
dict_stk_2_ind = {}
for stk in stock_list:
df = df_all[df_all["ts_code"] == stk]
if len(df) > 0:
dict_stk_2_ind[stk] = df.iloc[0]["l1_code"]
s_stk_2_ind = pd.Series(dict_stk_2_ind)宽度计算
到这里,最主要的问题、最难啃的步骤都已经啃完了。后面就是基于上面两类数据计算各个票的 乖乘率,以及每日 各个行业乖乘率大于 0 的票的比例。
# 计算乖乘率
df_close = adjusted_list_all.pivot(
index="ts_code",
columns="date",
values="close",
).dropna(axis=0)
df_ma20 = df_close.rolling(window=20, axis=1).mean().iloc[:, -count_:]
df_bias = df_close.iloc[:, -count_:] > df_ma20
# 每个交易日全市场的总体状况:close 在 MA20 之上的比例
s_mkt_ratio = ((100.0 * df_bias.sum()) / df_bias.count()).round()
df_bias["industry_code"] = s_stk_2_ind
df_ratio = (
(df_bias.groupby("industry_code").sum() * 100.0)
/ df_bias.groupby("industry_code").count()
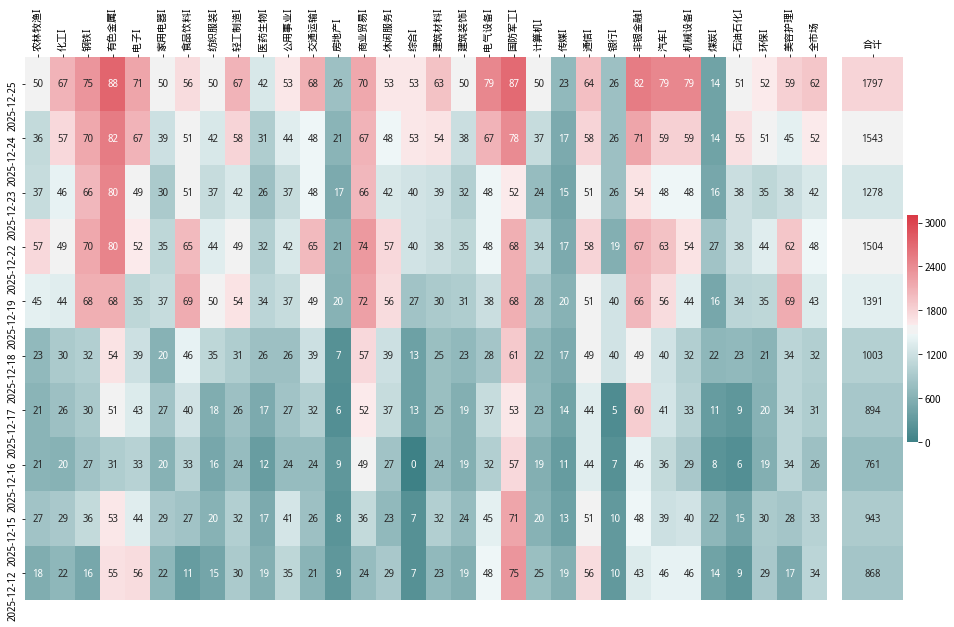
).round()我们将本地 Python 代码运行的结果,与聚宽上大佬们写的聚宽代码运行结果进行对比,结果基本一致,证明以上本地化过程是正确的。
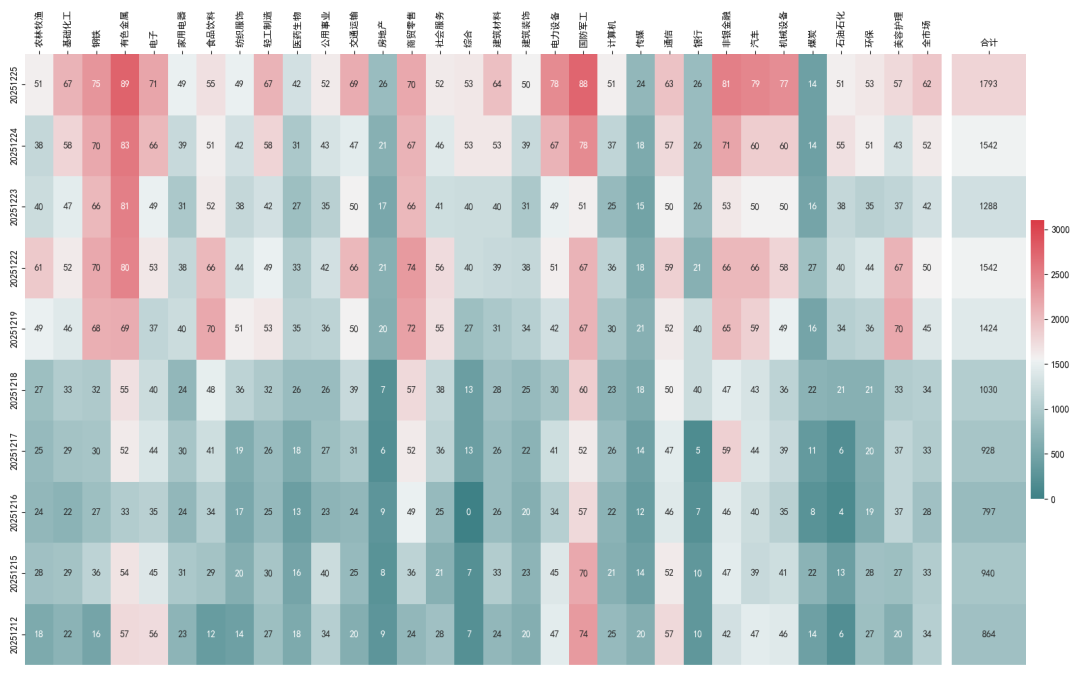
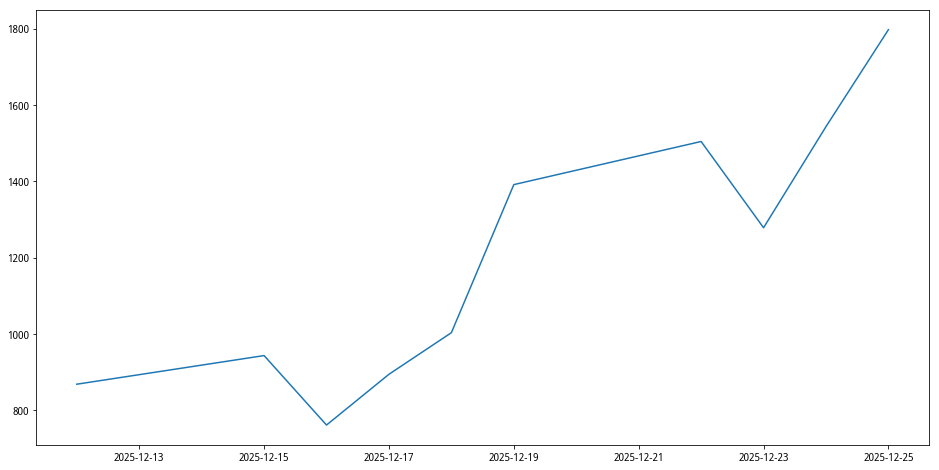
我们也可以比较一下 全市场宽度 的运行结果,也基本是一样的。
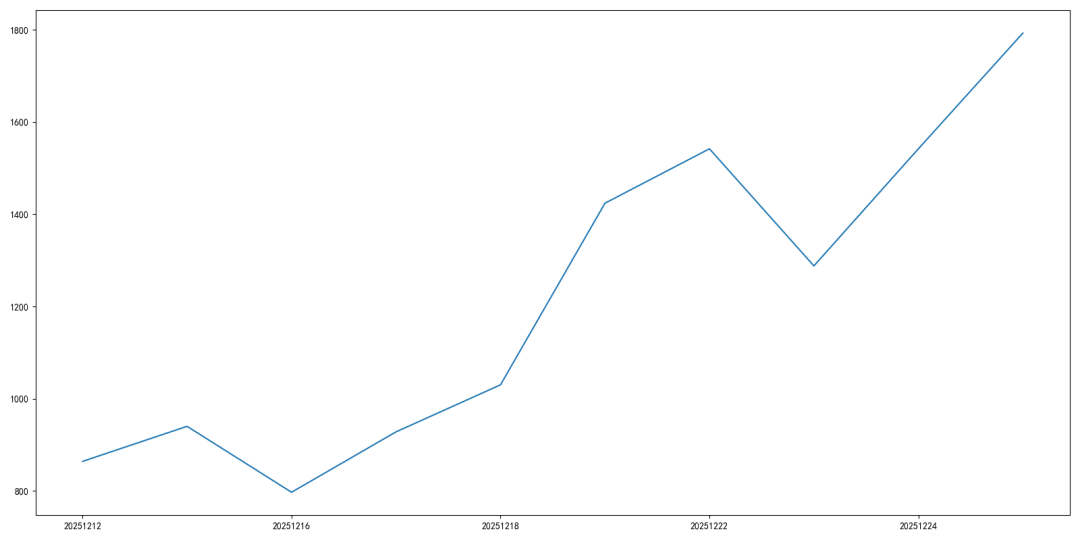
小结
整个流程走下来,最大的感受还是那句话:
本地 Python 量化虽然麻烦一点,但一旦工具链搭起来了,你就拥有了真正的自由。
- 不依赖第三方平台
- 数据、逻辑、代码全在自己手里
- 想怎么跑就怎么跑,想怎么改就怎么改
如果你也和我一样,对“可控性”和“自由度”有执念,那本地化这条路,真的很值得折腾。
希望这篇思路拆解,能对你有所启发。如果你也对 Python 本地量化感兴趣,欢迎加入知识星球,一起交流学习探索。
知识星球:不定期更新可本地运行的 Python 量化工具等代码,方便个人学习研究。代码持续更新,让 Bug 远离我们。同时也有交流群,大家一起探讨 Python 本地量化。

评论与交流
当前主要通过知识星球和社交媒体交流文章相关问题。
交流入口
如果你想讨论文章里的代码、数据接口或本地运行问题,可以通过知识星球或页脚社交媒体联系我。