
本文仅用于学习研究与技术交流,不构成任何投资建议。
大家广为所知的ETF轮动策略,一般采用固定的ETF候选池,再结合固定时间窗口来计算动量,最终轮动持有动量最高的那一只。
常见的ETF池子通常包含:纳指、黄金、创业板、红利或者上证180ETF等。
虽然很多人认为,这种ETF池子的定义本身存在一定的未来函数,但从底层逻辑来看,它其实是成立的:本质上就是在全球主要资产之间进行动态配置和轮动,从而捕捉不同阶段的市场主线。
⚡ 改进策略
年前在聚宽上看到一篇对基础版ETF轮动进行改进的策略,回测效果非常不错。原策略链接:https://www.joinquant.com/post/62821
最近一直忙着带娃,没太多时间研究这个,这几天才断断续续对该策略进行了研究,并实现了本地化(没错,我就喜欢搞搞本地化)。
这个改进版策略主要包含以下几个优化点:
1. 基于波动率动态调整动量回溯窗口
传统ETF轮动策略通常采用固定回溯窗口(例如25天)来计算动量。但不同ETF的波动特征差异很大,固定窗口并不一定合理。
改进策略的核心思路是:
-
对于波动较小的ETF,采用较长的回溯期,从而更好地捕捉长期趋势;
-
对于波动较大的ETF,采用较短的回溯期,以提高对短期行情的敏感度。
回溯窗口基于ATR波动率指标进行动态调整,核心公式如下:
lookback = lb_min + (lb_max - lb_min) * (1 - min(ratio_cap, vol_ratio))其中:
vol_ratio: 短窗口波动率 / 长窗口波动率lb_min和lb_max: 回溯窗口大小边界,例如取10天和60天。ratio_cap: 比例阈值,例如取0.9。
这一改动本质上是让动量指标更加自适应不同资产的波动特征,从而提高策略稳定性。
2. 引入ETF溢价率因子
如果某只ETF当前溢价率过高,则在计算动量评分时进行惩罚。
原因很简单:高溢价往往意味着短期资金拥挤,后续存在均值回归风险。
因此,在动量模型中加入这一因子,有助于降低追高风险,提升策略的风险控制能力。
3. 过滤近期大幅下跌的ETF
第三个改进,是加入趋势过滤:
- 过滤近期出现大幅下跌的ETF
- 过滤近期连续下跌的ETF
这一规则的核心思想是:避免在明显的下跌趋势中“抄底”,从而降低回撤。
def has_large_recent_drop(prices: np.ndarray) -> bool:
if len(prices) < 5:
return True
con1 = min(prices[-1] / prices[-2], prices[-2] / prices[-3], prices[-3] / prices[-4]) < 0.95
con2 = (prices[-1] < prices[-2] < prices[-3] < prices[-4]) and (prices[-1] / prices[-4] < 0.95)
con3 = (prices[-2] < prices[-3] < prices[-4] < prices[-5]) and (prices[-2] / prices[-5] < 0.95)
return bool(con1 or con2 or con3)💻 策略本地化实现
这套策略的逻辑并不复杂,所需数据在Tushare中基本都可以获取,因此完全可以在本地实现。
具体包括:
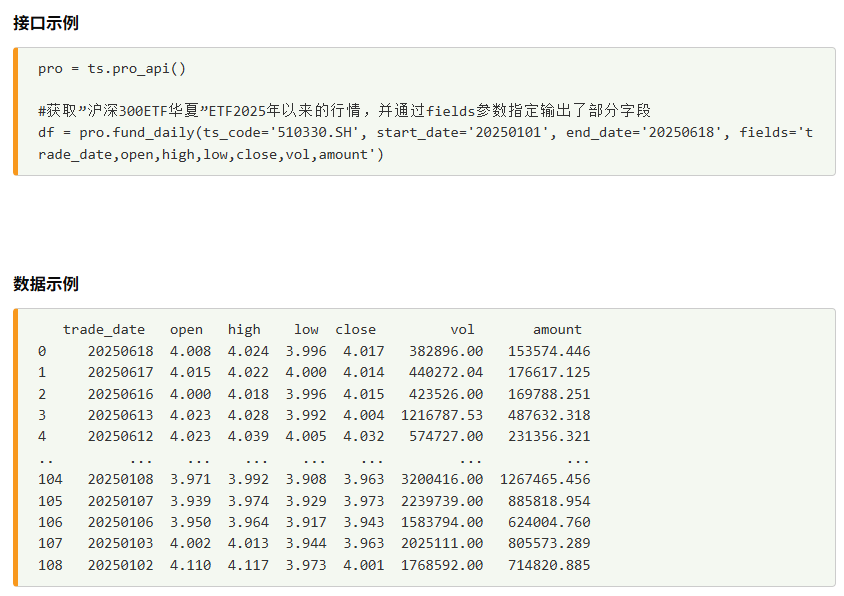
1)ETF行情数据
可以通过 Tushare 的fund_daily接口获取。
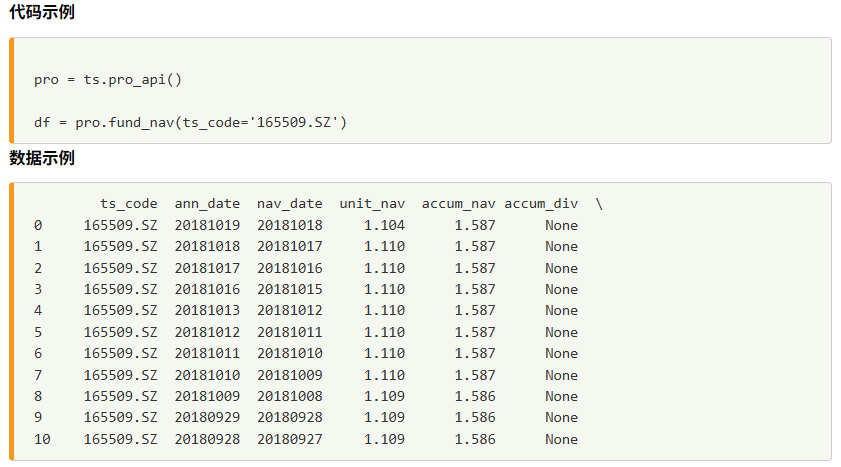
2)ETF溢价率计算
溢价率计算需要基金单位净值信息,该数据可以通过 Tushare 的fund_nav接口获取。
for code in etf_codes:
try:
df = pro.fund_nav(ts_code=code, start_date=start_date, end_date=end_date)
except Exception:
continue
if df is None or len(df) == 0:
continue
# 这里应该优先用 ann_date
date_col = next((c for c in ["ann_date", "nav_date", "trade_date"] if c in df.columns), None)
nav_col = next((c for c in ["adj_nav", "unit_nav", "accum_nav"] if c in df.columns), None)
if date_col is None or nav_col is None:
continue
tmp = df[[date_col, nav_col]].dropna().copy()
if tmp.empty:
continue
tmp[date_col] = tmp[date_col].astype(str)
tmp[nav_col] = pd.to_numeric(tmp[nav_col], errors="coerce")
s = (
tmp.sort_values(date_col)
.drop_duplicates(subset=[date_col], keep="last")
.set_index(date_col)[nav_col]
.dropna()
)
if not s.empty:
nav_history[code] = s3)动量计算的实时处理
原策略中使用了当日的实时行情参与动量计算。
在本地环境中,由于只有日线数据,因此采用当日开盘价来近似替代实时价格,从而提高策略的现实可执行性。
在实时运行中,可以用Tushare的realtime_quote接口来获取实时行情,然后并入序列进行动量计算。

def calc_score(prices: np.ndarray) -> Optional[Dict[str, float]]:
if len(prices) < 5:
return None
if np.any(~np.isfinite(prices)) or np.any(prices <= 0):
return None
y = np.log(prices)
x = np.arange(len(y), dtype=float)
weights = np.linspace(1.0, 2.0, len(y))
try:
slope, intercept = np.polyfit(x, y, 1, w=weights)
except Exception:
return None
annualized_returns = math.exp(slope * 250) - 1
y_hat = slope * x + intercept
ss_res = np.sum(weights * (y - y_hat) ** 2)
ss_tot = np.sum(weights * (y - np.mean(y)) ** 2)
r2 = 1 - ss_res / ss_tot if ss_tot else 0.0
score = annualized_returns * r2
return {
"annualized_returns": float(annualized_returns),
"r2": float(r2),
"score": float(score),
}📈 策略回测
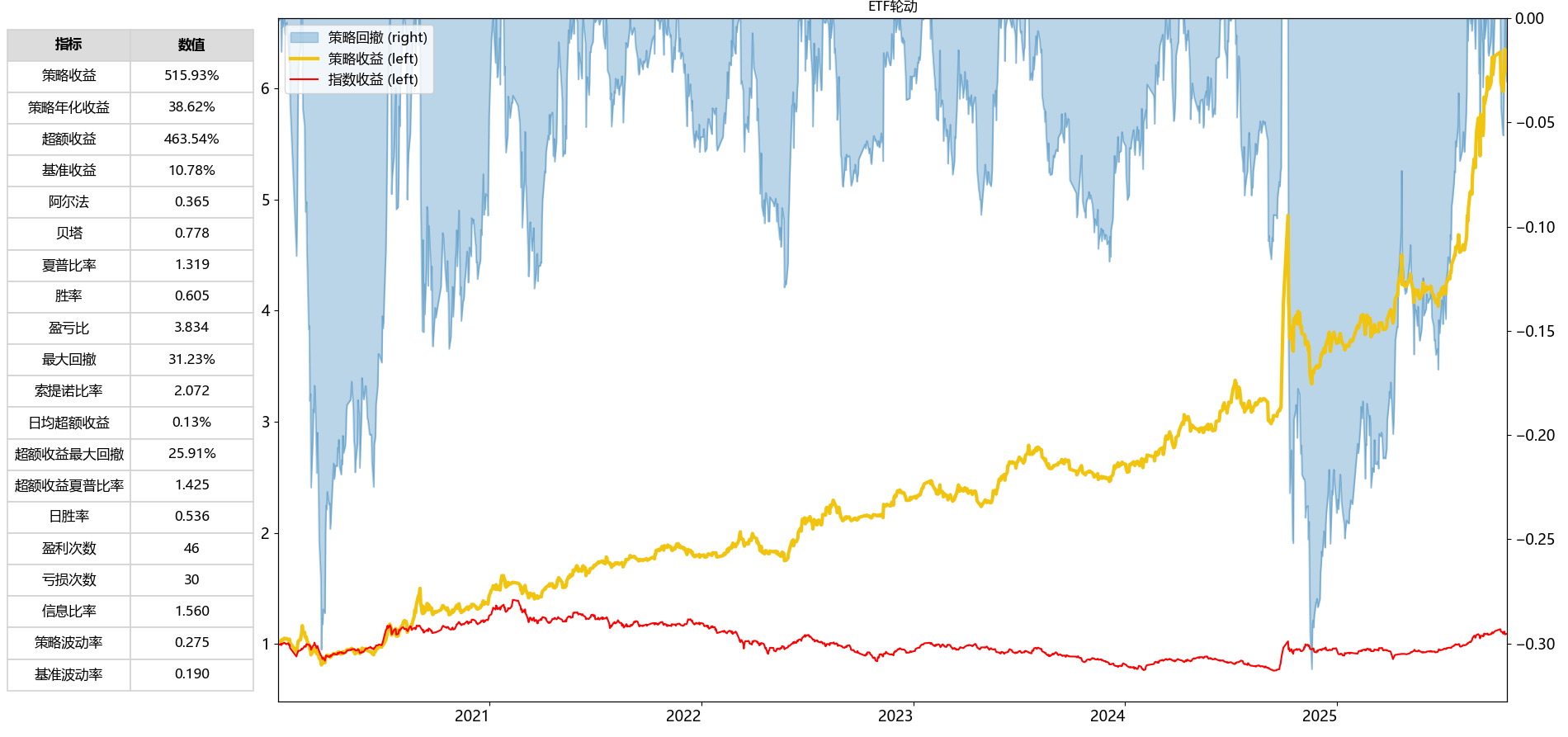
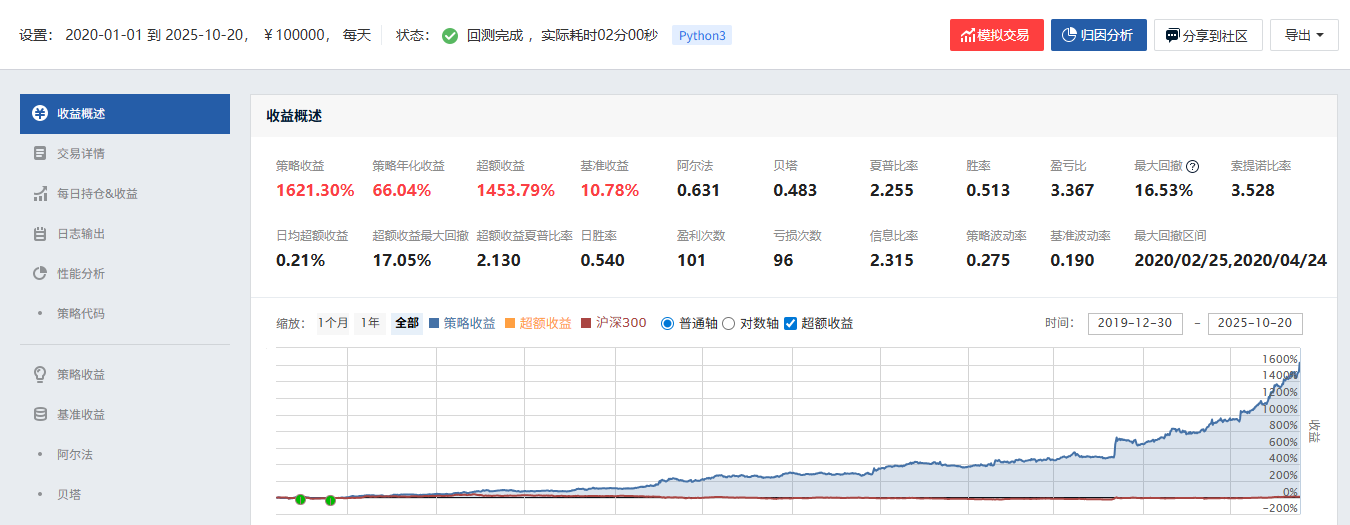
本地回测发现:长期年化为 60.42%,最大回撤为 18.79%。与聚宽回测结果一致,大致说明本地化的正确性。
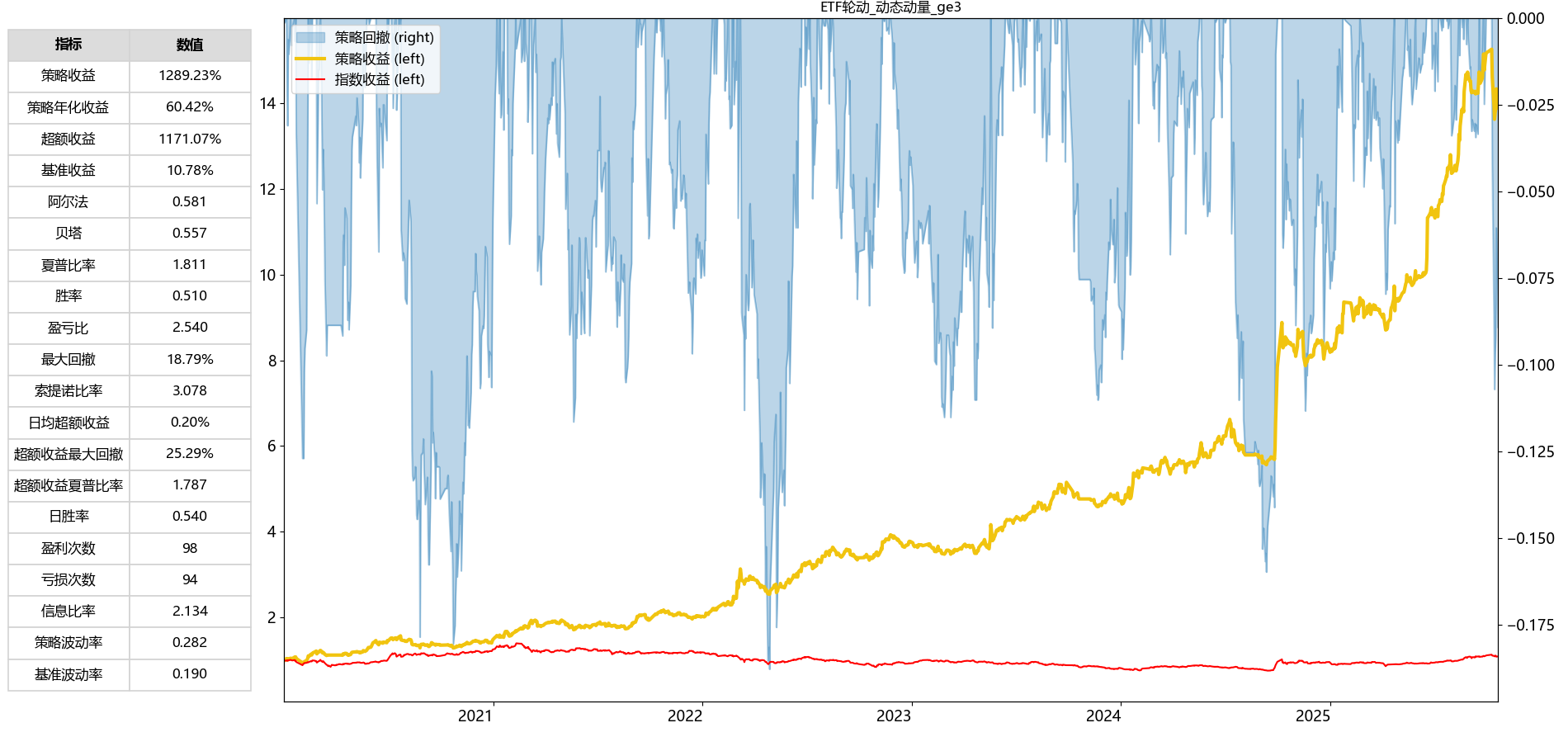
相比基础版的ETF轮动策略,该策略确实有明显提升,最大回撤降低了不少。
| 指标 | 基础版 | 改进版 |
|---|---|---|
| 年化 | 38.62% | 60.42% |
| 夏普比率 | 1.319 | 1.811 |
| 最大回撤 | 31.23% | 18.79% |
但如果只回测2025年至今的表现,效果会显得非常惊人。
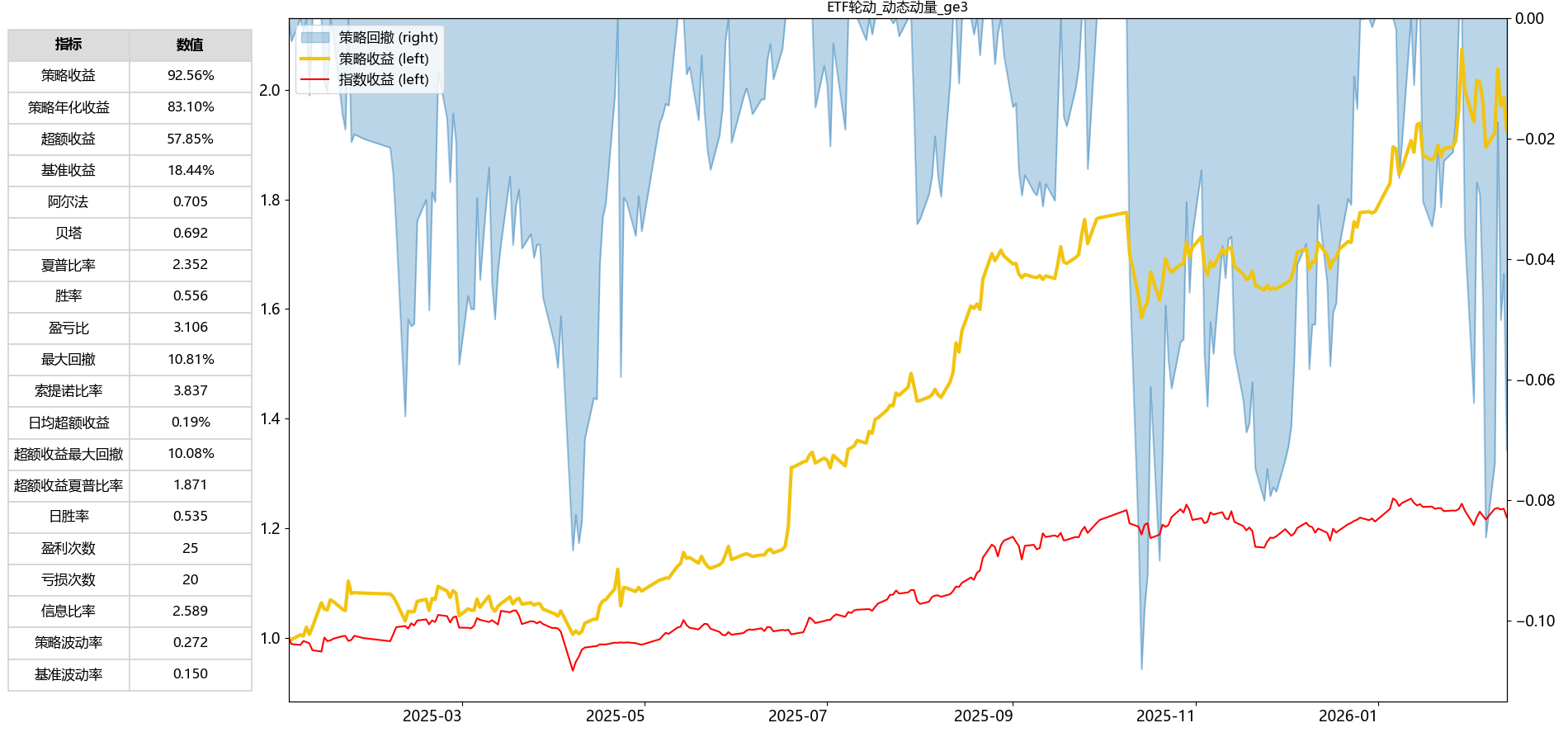
主要原因大概是ETF候选池中包含了多只在2025年表现极为强势的ETF,因此存在一定的“隐性未来函数”问题。
不过即使剔除这一因素,从长期表现来看,该策略依然具备较好的稳定性和收益特征,仍然是一个值得关注的方向。
🎯 ETF候选池
对于ETF轮动策略,最核心的问题还是:
ETF轮动策略的候选池,究竟该如何定义?
1) 主观定义
在真实交易中,我们完全可以根据当前市场行情,定期更新ETF候选池,以捕捉阶段性的强势资产。例如考虑宏观周期变化、短期政策驱动、行业主线、全球风险偏好等。但这种动态调整在回测中往往难以实现,因为容易引入主观偏差。
2) AI构建ETF候选池
我们之前也尝试过,用AI来构建短期未来的ETF候选池。这是一种更加动态和前瞻性的方式。例如利用AI分析宏观环境,挖掘潜在市场主线,动态生成候选资产池。当然,这类方法的有效性,必须通过长期实时运行来验证。
🚀 写在最后
本文主要介绍了该策略的本地化实现,并未对策略进行深入优化。
因为我们已经搭建了完整的模拟盘框架,因此可以将该策略接入模拟盘进行实时跟踪和验证。
策略是否真正有效,最终一定要交给市场。
敬请期待后续实际运行表现。
评论与交流
当前主要通过知识星球和社交媒体交流文章相关问题。
交流入口
如果你想讨论文章里的代码、数据接口或本地运行问题,可以通过知识星球或页脚社交媒体联系我。